Citation Extraction Guide
This article will describe a case-study in extracting a BibTeX citation from a Wikidata scientific article.
Finding the Citation on Wikidata
First: select an article to extract a citation from. For our case study, we will be using this article. After selecting an article, we must be aware of what academic database we are extracting our citation from, as BibTeX formats vary between databases. These can be found in the identifiers of the article.
The article we are using has two possible candidates (DOI is discarded due to lack of specificity, and ResearchGate is discarded due to it operating as an aggreggate citation collector and thus having more inaccuracies than average.).
PubMed uses the mbib citation style, which we are not currently prioritising. As an aside, I do think it would be worthwhile to consider making our program be compatible with mbib, for two reasons:
- A lot of scientific articles have a PubMed identifier, one which is often used to state author names in the first place
- PubMed citations specifically contain an author full name keyword, which may help guarantee that we are dealing with full names, not abbreviations.
As the mbib citation style is very similar to RIS, I don’t think implementing it would be an egregious amount of extra work.
Extracting the Citation from the Database
Back to the case study! Seeing as we will not be using PubMed for this article, we will instead use the article’s Dimensions Publication ID. This will first be done manually: before programming a citation finder, we, as humans, need to understand where to find it.
In Dimensions Publication, we can see an ‘Export Citation’ button on the right of the page. When pressed, an API is called that gets the BibTeX citation as a .bib text file, which will be saved to a variable when programmed.
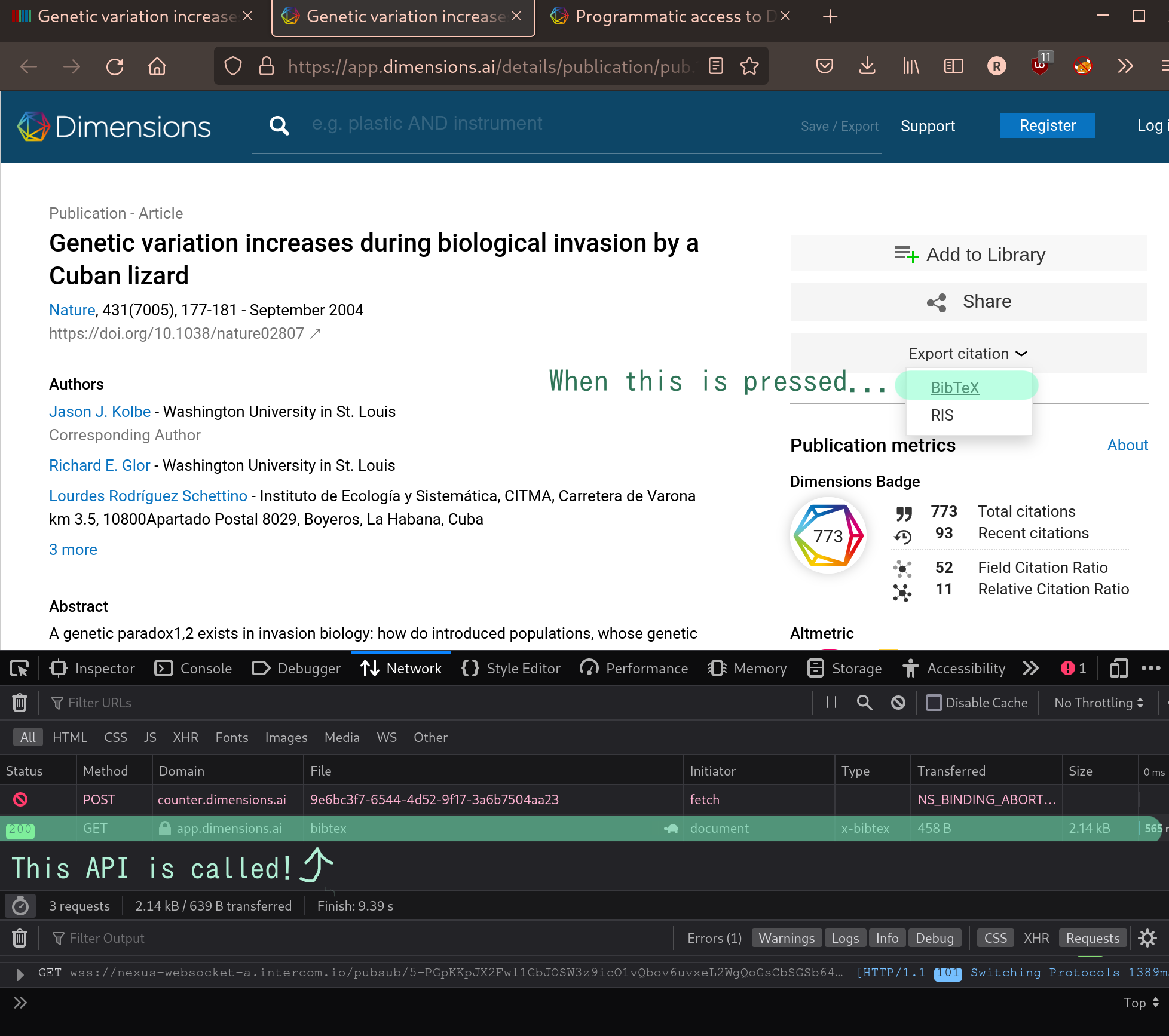
Let’s take a look at the bibTeX API url: https://app.dimensions.ai/details/sources/publication/export/pub.1023107623/citation/bibtex. Click on it to see the BibTeX file it generates!
This appears to be a standardised API, with the numbers after pub. corresponding to the Dimensions Publication ID we can find on Wikidata. It follows that as long as we know the aforementioned API URL, we can get the BibTeX citation for any article on WikiData that has a Dimensions Publication ID.
Some scientific databases, such as ADS, may provide more robust APIs that allow for more efficient citation extraction. For this reason, I believe the best approach to this project would be to create a program that has a list of databases it is compatible with, which it attempts to find in the article in a prioritised order based on the reliability of the site, and maybe even the reliability of the site in regards to certain languages. This means we could potentially get databases like ResearchGate working, but have them be used as a last resort).
The next step after getting the BibTeX file is to parse the file in a way that accurately gives us the first and last names of an author. Let us manually evaluate the author section in the BibTeX file:
author = {Kolbe, Jason J. and Glor, Richard E. and Rodríguez Schettino, Lourdes and Lara, Ada Chamizo and Larson, Allan and Losos, Jonathan B.},
Author names, in Dimensions Publication files, work as follows:
- The first author surname can be found by finding the first character that follows
author = { - The last author can be detected by checking for when an author first name is followed by a
}, - Author first names and last names are separated by a
, - Author last names are separated by the word
and - IMPORTANT: This is a Dimensions Publications file that appears to accurately deal with Latin-American names. Take this into consideration for future citation extraction.
Having manually gathered all required rules for parsing citations in BibTex Dimensions Publication files, we can proceed to extract these using RegEx. The rest of the program should be fairly straight-forward: Extract first and last author names and put these in two separate arrays (or one 2D array), search for the author on Wikidata and add them as an author if found or as an author name string if not found, making sure to add series ordinal for both authors and author name string, as well as object stated as qualifiers for authors.
I believe the best way to proceed is to write a generalised program that searches the queries mentioned above and procedurally adding compatible databases to continually make the program more robust. I believe this method will also allow for easy modifications in the future: If users want to add a specific database to the program, I see no reason why they should not be able to.